사용한 라이브러리
requests, bs4, Konlpy, matplotlib, wordcloud, counter
실행한 페이지
>나무위키 베스트 라이브
<목차>
1. 실행할 페이지 스크래핑
2.Konlpy Okt()를 통해 형태소 분할하기
3.분할한 형태소 자료 가공하기
4. 워드 클라우드 만들기
1. 실행할 페이지 스크래핑
> 나무위키 베스트 라이브의 페이지 1부터 49까지 스크래핑을 해보겠습니다.
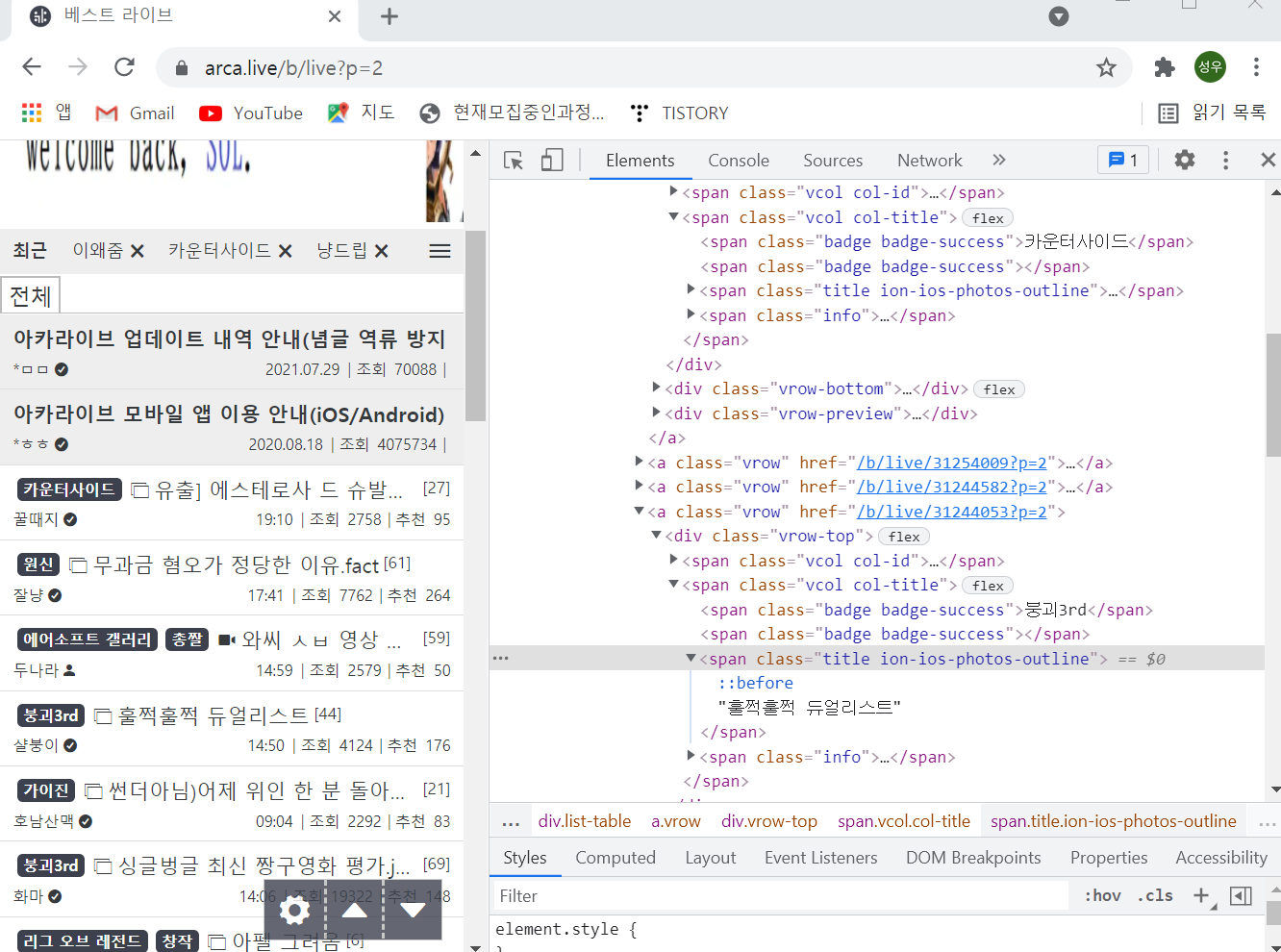
먼저 스크래핑을 시행할 페이지로 이동해서 게시판의 주소 구조와 개발자 도구를 이용해 html구조를 살핍니다.
게시판의 주소는 arca.live/b/live?p=2
지금 페이지가 2페이지니까 페이지는 p값으로 이동한다는 것을 알았습니다.
그리고 html 구조를 보면 class명이 title ion-ios-photos-outline인 span에 제목이 들어가 있는 것을 확인할 수 있습니다.
이러한 정보를 바탕으로 스크래핑을 시행할 수 있습니다.
그렇다면 이제 주피터 노트북을 켭니다. 그리고 필요한 라이브러리들을 불러옵니다.
rows라는 리스트형 변수를 하나 지정해줍니다.
모든 텍스트가 담겨질 리스트입니다.
그리고 requests와 bs4를 이용하여 제목들을 스크래핑해줍니다.
그리고 rows 리스트에 모두 삽입해줍니다.
코드는 아래와 같습니다.

그리고 프린트해 보면 아래와 같이 잘 가져온 것을 볼 수 있습니다.

2.Konlpy Okt()를 통해 형태소 분할하기
Okt()를 통해서 형태소를 분할할 것입니다. 그래서 Okt()를 okt로 지정해주고 또 하나의 리스트인 word를 만들어 줍니다.
이 word에는 Okt로 분할한 형태소와 그 태그가 담긴 자료('단어','tag')가 담길 것입니다.
rows의 길이만큼 반복해주면서 rows안의 글들을 형태소로 분할하여 words에 저장해줍니다.


다시 리스트 nounlist를 만들어줍니다.
이 리스트에는 noun 즉 명사형 형태소만이 들어갈 것입니다.
그래서 태그가 noun인 단어들을 if 조건문으로 선별하여 추가해줍니다.


프린트 하여 결과를 확인하면 잘 들어가있음을 확인할 수 있습니다.
다음으로 Counter 라이브러리를 활용하여 안에 들어 있는 명사들의 빈도수를 dic형으로 만들고 다시
count.most_common()을 이용해 최빈값부터 아래로 정렬해줍니다.

실행해 보면 잘 나옵니다.

다만 빈도가 1이거나 2와같은 단어들이 너무 많음으로 5번 이상 나온 명사로 한정합니다.
3.워드클라우드를 만듭니다.
font를 지정하고, 배경색, 컬러, 워드클라우드의 크기를 지정해주고, 문자들의 크기의 척도를 빈도로 설정해줍니다.
그리고 plt를 사용해 직접 나타내주면 워드클라우드가 완성됩니다.


*konlpy가 다루기가 까다롭습니다. 처음 하시는 분이라면 수많은 오류에 봉착하실것입니다.
그래서 구글링을 통해서 해결을 하시려 노력을 하실텐데, 그 중에 자바 경로를 지정해야한다는 이야기가 있을 것입니다.
Java_home 경로를 지정할 때 최근의 자바는 java_home을 따로 우리가 지정하는 것이 아니라 자신들이 깔자마자 경로를 만들어 주는 것으로 알고있습니다. 그래서 java_home 경로를 지정할때 oracle이 적혀있는 자바 경로가 이미 있지 않은지 잘 살펴보셔야 할것입니다.
긴 글 읽어주셔서 감사합니다.
'데이터분석 > 분석 예제' 카테고리의 다른 글
| <React> 공공데이터 API 불러오기(한국도로공사 OpenAPI) (0) | 2021.11.17 |
|---|---|
| 서울 코로나 요일별 확진자 비율 (2020.01.24~ 2021.08.17 ) (0) | 2021.08.27 |
| 서울 일별 코로나 확진자 수 그래프 그리기 (0) | 2021.08.26 |