<목차>
1. 생략된 row나 column 모두 표시하기
<pd.set_option('display.max_rows,nn) 또는 pd.set_option('display.max_columnss,nn)>
2. 데이터 형을 확인하고 숫자형 자료형으로 변경하기
df.dtypes, pd.to_numeric
3. 필터 생성하여 검색하기
4. 정렬하기와 인덱스 지정하기
df_sort_by_values, df.set_index
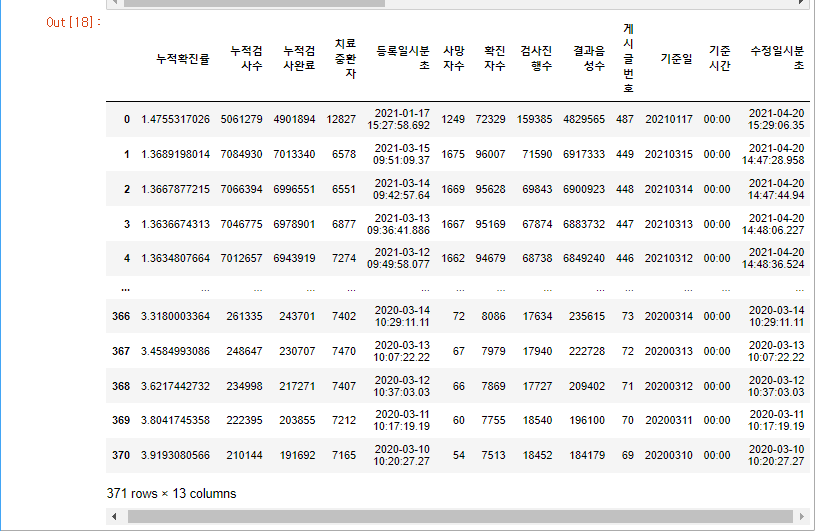
지금까지 알아보았던 것들을 복습도 할겸
371rows와 13개의 column을 가지고 있는 코로나 관련 공공데이터를 가지고 왔습니다.
1. 생략된 row나 column 모두 표시하기
df 에 넣어서 출력했더니 너무 길어서 중간에 생략을 했습니다.
이렇게 생략된 자료를 보기 위해서는 pd.set_option('display.max_rows',371)을 사용해 줍니다.
* column의 수가 많아 생략이 되었다면 pd.set_option('display.max_columns',원하는 길이)를 사용해주면 됩니다.
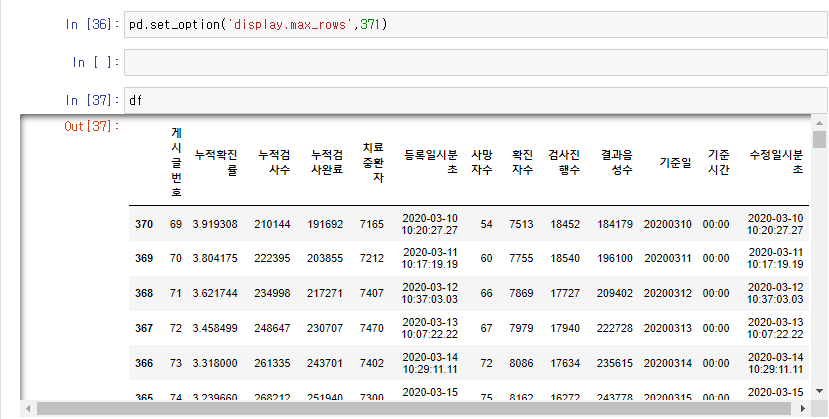
그러면 모든 열이 다 나오는 것을 확인 하실 수 있습니다.
2. 데이터 형을 확인하고 숫자형 자료형으로 변경하기
이렇게 가져온 데이터들에 보이는 숫자들이 사실 int형이 아닙니다.
CSV로 되어있는 자료형은 숫자로 인코딩되어있지만, xml 자료에서 직접 parsing 한 자료들은 모든 자료형이 object형이거나 string , navigatedstring으로 표시가 될 것입니다.
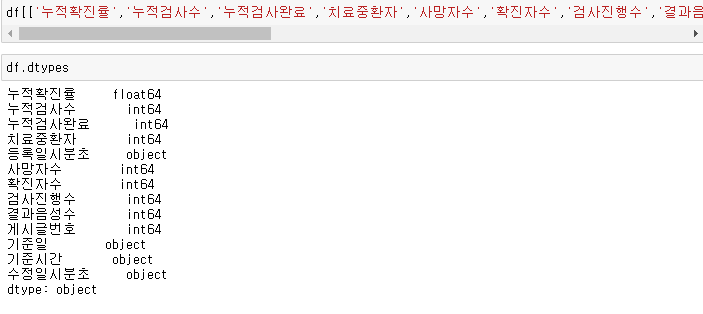
데이터 타입을 확인해 보겠습니다.
df.dtypes를 입력하면 됩니다.

모든 데이터들이 object형입니다.
이렇게 되면 숫자로서 값을 비교하거나 연산은 불가능합니다.
그러므로 다시 이 값들을 숫자형 자료로 바꿔줍니다.
Pandas에 내장되어있는 to_numeric을 사용해주면 됩니다.
숫자형으로 바꿔줘야할 column들로
누적확진률 누적검사수 누적검사완료 치료중환자 사망자수 확진자수 검사진행수 결과음성수 게시글번호
가 보이는 군요.
그렇다면 아래와 같이 적용해주면 됩니다.
df[['누적확진률','누적검사수','누적검사완료','치료중환자','사망자수','확진자수','검사진행수','결과음성수','게시글번호']] = df[['누적확진률','누적검사수','누적검사완료','치료중환자','사망자수','확진자수','검사진행수','결과음성수','게시글번호']].apply(pd.to_numeric)
*반드시 대괄호를 두번 입력하셔야 list형으로 인식을 합니다.
그리고 다시 데이터형을 확인해보면
3. 필터 생성하여 검색하기
그럼 이제 필터를 만들어 적용해보겠습니다.
저는 누적 사망자수가 1000명이 넘은 날 기준일과 기준시간 그리고 누적 사망자수를 알고싶습니다.
그렇다면 이렇게 필터를 짜고 df.loc를 실행해 주면 되겠지요.

4. 정렬하기와 인덱스 지정하기
이제 인덱스를 기준일로 바꾸고 싶습니다. 그리고 오래된 순부터 표를 보고 싶습니다.
그럴때는 기준일을 기준으로 삼아서 오름차순으로 표를 변경한 후에 인덱스를 기준일로 변경해주면 되겠지요.
df_sort_by_values는 columns 안의 값들을 특정한 조건에 맞게 정렬해주는 기능을 합니다.
df.sort_values(by = '기준일', ascending = True, inplace = True)
에서 by는 기준이 될 column의 이름을 넣는 곳이고 ascending은 오름차순이라는 뜻이기에 True을 넣어주면 됩니다.
그리고 영구적 반영을 위해 inplace에 True를 넣어줍니다.
그리고 실행을 하면
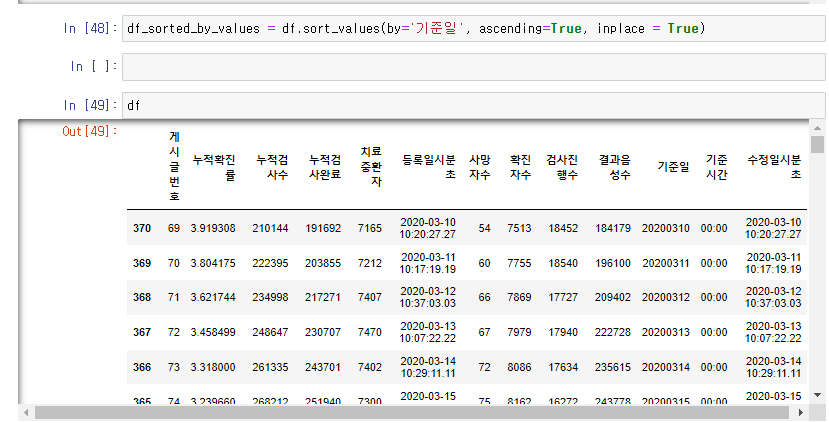
오래된 순부터 표가 출력됨을 볼 수 있습니다.
이제 df.set_index('기준일',inplace = True)를 통해 인덱스 값을 기준일로 바꿔줍니다.
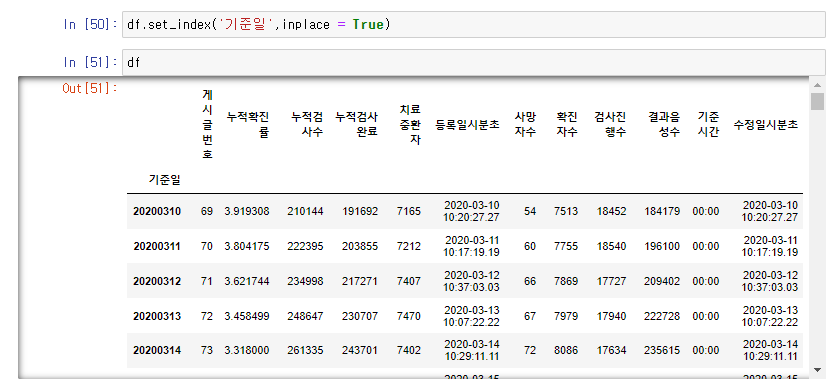
그리고 여기서 다시 앞의 필터를 적용해봅니다.
주의해야 할 것은 이제 기준일은 인덱스임으로 보고 싶은 변수자리에 넣지 않습니다.
그래도 인덱스니 출력이 됩니다.
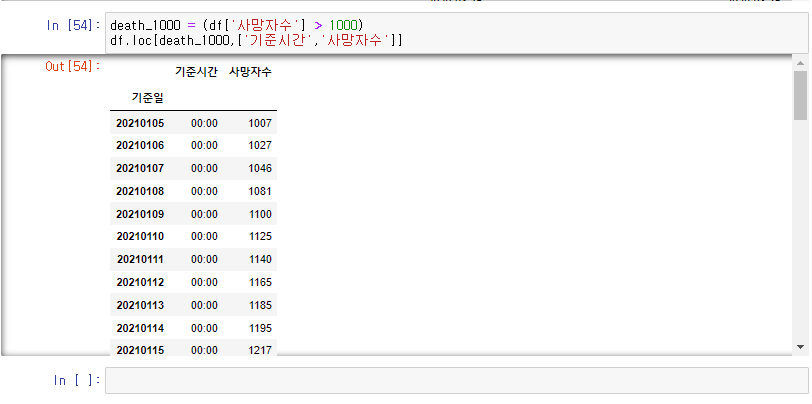
잘 출력되는 것을 볼 수 있습니다.
지금까지 앞에서 살펴보았던 기능들이 큰 데이터에서 어떻게 적용이 되는가를 알아보았습니다.
긴 글 읽어주셔서 감사합니다.
'데이터분석 > Python Pandas' 카테고리의 다른 글
| <pandas> 6. columns 내용 변경하기 (map,replace) (0) | 2021.08.11 |
|---|---|
| <Python Pandas> 5.Column 이름과 Rows 변경하기 1 (0) | 2021.08.03 |
| <Pandas 사용하기> 3.검색 필터 작성하기 [1] (0) | 2021.08.01 |
| pandas 사용하기 2 index 바꾸기 (df.set_index()) (0) | 2021.07.30 |
| <Python> Pandas 사용하기 [list와 dictionary 자료형의 사용] (0) | 2021.07.30 |