☆parsing에 대한 노하우가 조금 쌓인 후에 보니 엉성하기 짝이 없는 글입니다.
그나마 발전한 이 페이지로 이동해주셔서 보시면 감사하겠습니다.☆
https://operstu1.tistory.com/87
어느 정도 노하우가 쌓인 xml 공공데이터 parsing과 CSV 저장
<목차> * 필요한 라이브러리 1. 파싱하기 전에 반드시 해야 할것 1)미리보기를 통한 데이터형태 파악하기 2)참고문서 다운받기 2. 파싱시작하기 1) 라이브러리 불러오기 2) 요청 명세를 보고 u
operstu1.tistory.com
♧다만, 원시적인 방법을 사용한 만큼 처음이신분이라면 이글이 더 쉬울수 있습니다.♧
오늘은 파이썬을 이용하여 xml로 된 공공데이터안의 데이터를 불러와 보겠습니다.
*사용한 라이브러리 : requests, bs4
**사용한 공공데이터 : 공공데이터활용지원센터_보건복지부 코로나19 감염 현황
먼저 공공데이터 포털로 가서 필요한 데이터를 가지고 와야겠지요.
여기에 들어오신 분들은 이미 데이터를 가지고 파싱하는 도중에 문제가 생겼거나 하려고 하는 분들이 대부분일테니
공공데이터 포털 사용법은 생략하도록 하겠습니다.
바로 시작하도록 하겠습니다.
(1) BeautifulSoup과 requests 패키지를 불러옵니다.

(2) 개별정보 상세보기로 들어가서 참고 문서를 다운받아 줍니다. 그리고 인증키(encoding)을 복사해줍니다.
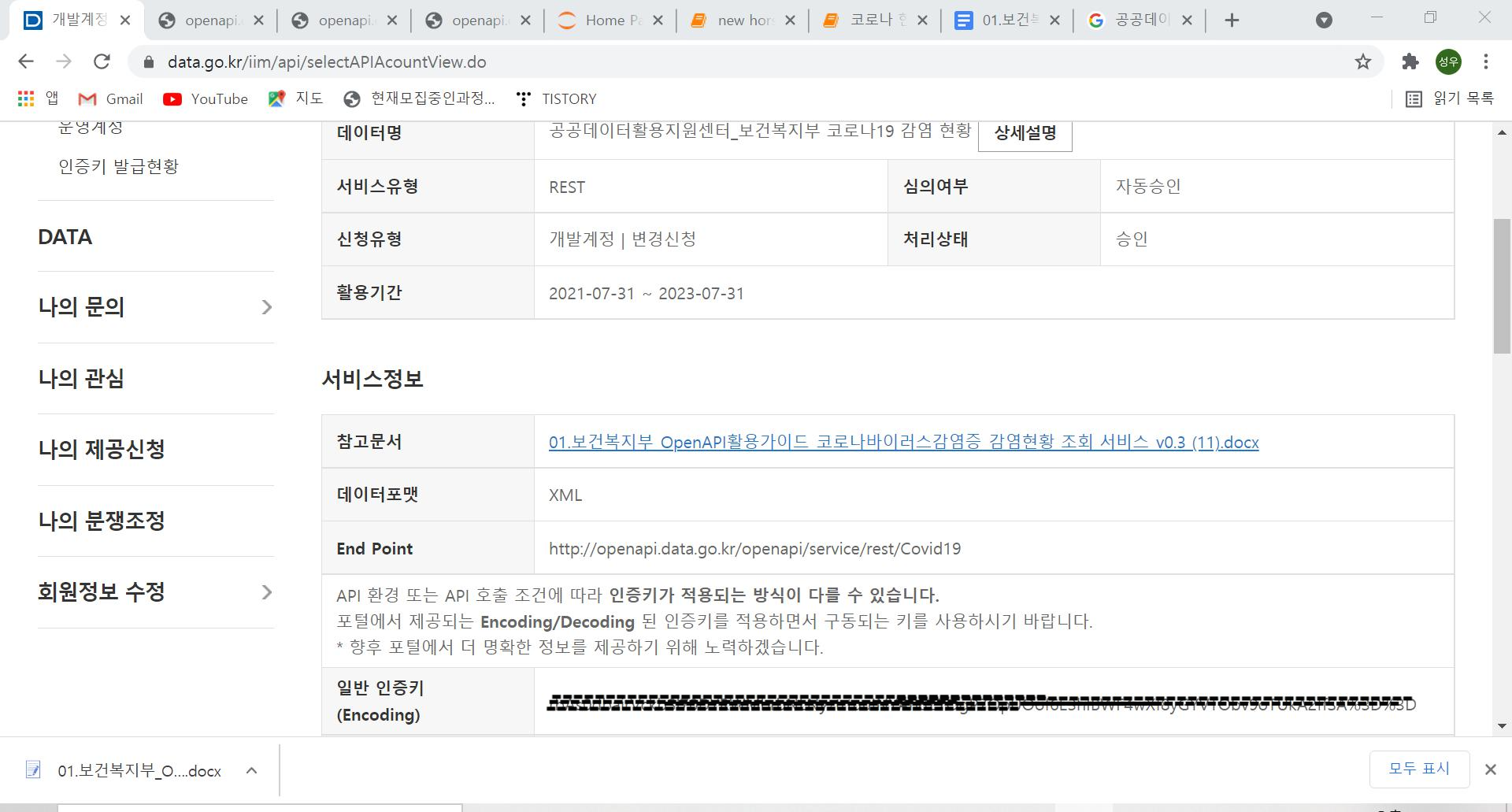
(3) 미리보기에 확인을 눌러 요청변수들이 어떤 것들인지 이해합니다.
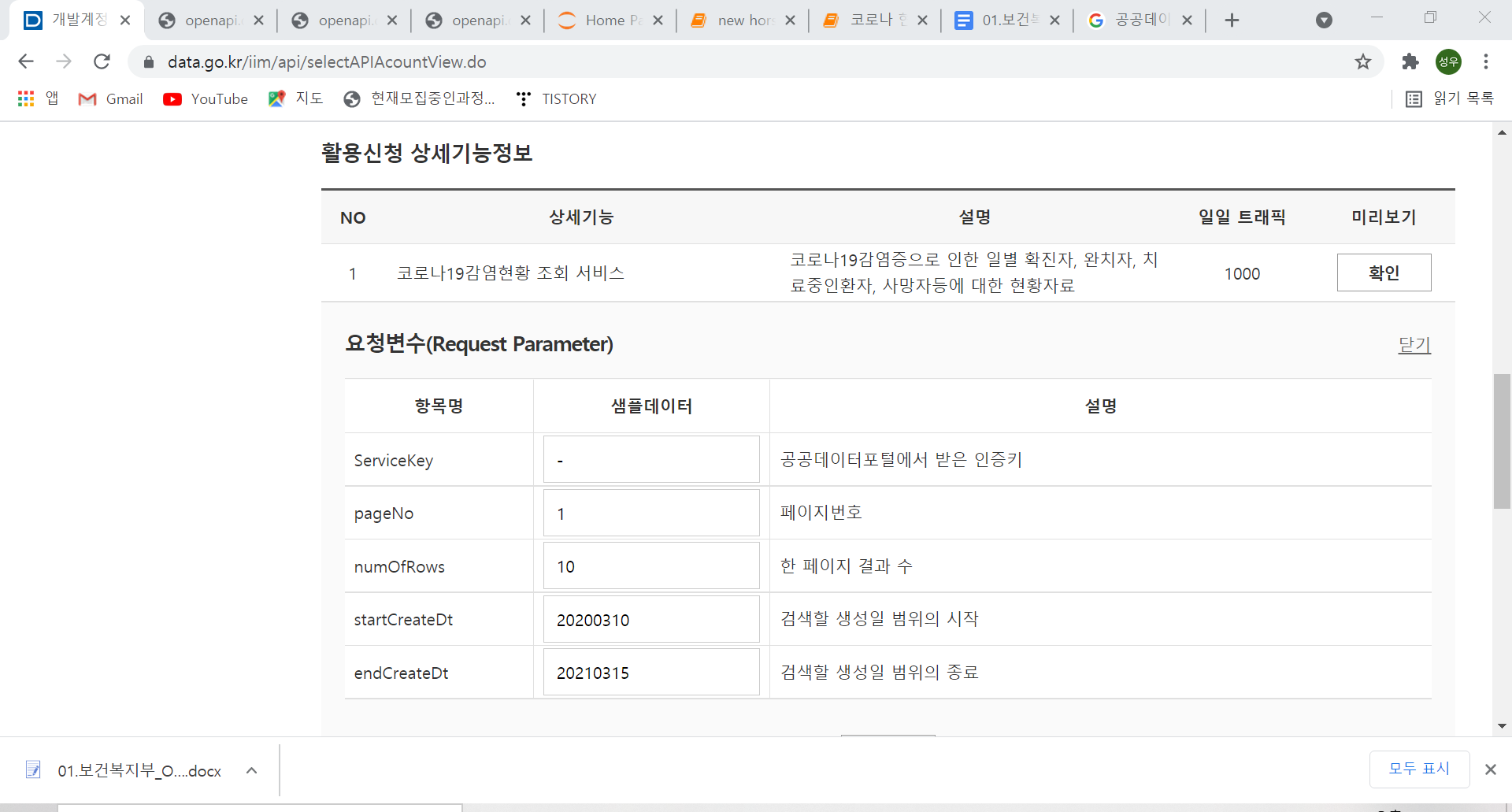
* numOfRows 는 한 페이지 결과 수 이고, startCreateDt는 검색할 생성일 범위의 시작이고, endCreateDt는 생성일 범위의 종료 날짜입니다.
이것을 잘 보셔야합니다.
(3) 다운받은 참고 문서에 들어가 open API 활용가이드에 요청 메세지를 그대로 복사합니다.
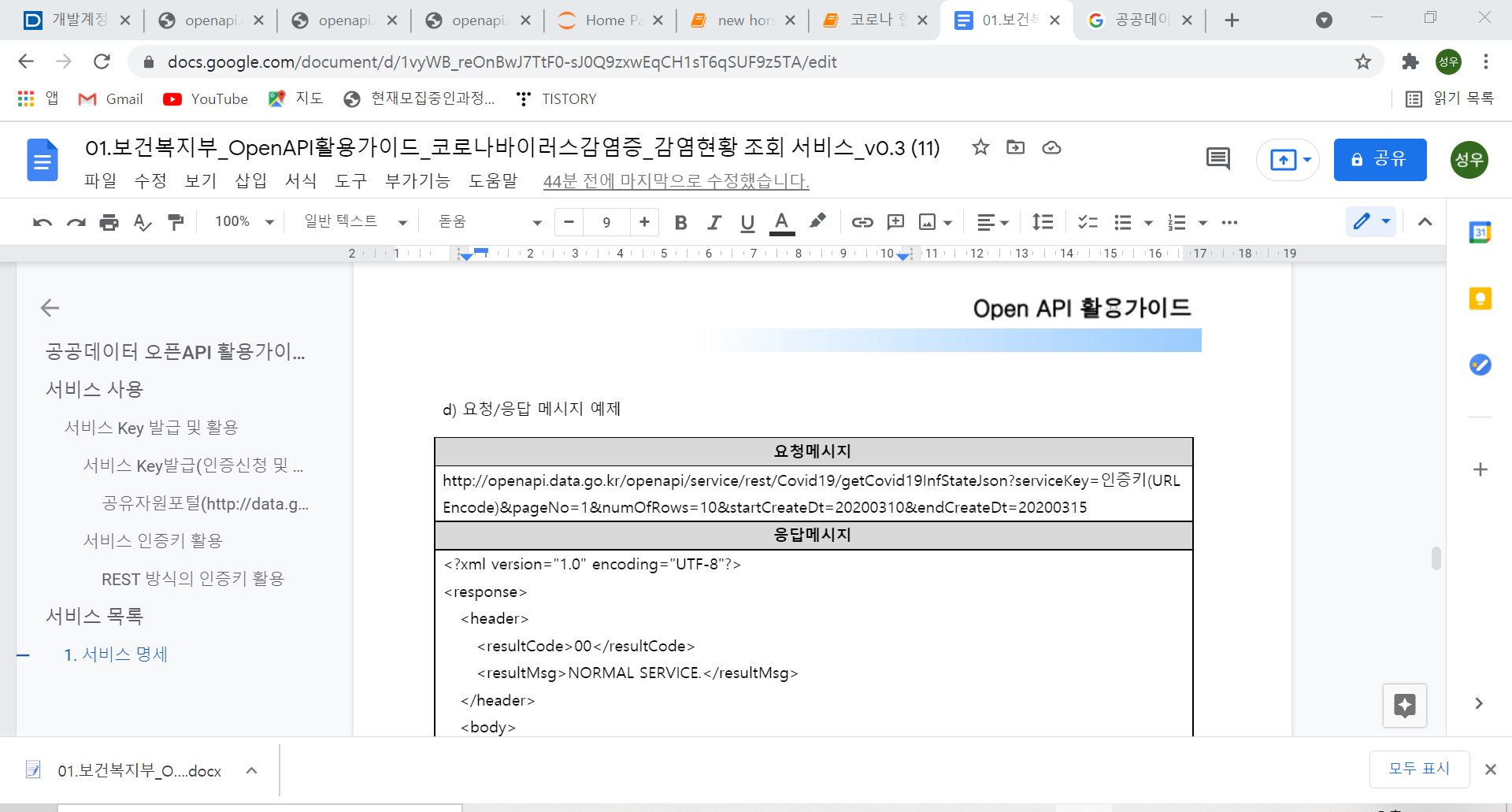
(4) 다시 파이썬으로 와서 url 에 붙여넣어줍니다.


url을 잘보시면 '인증키(url Encode)','pageNo', 'numOfRows', 'startCreateDt', 'endCreateDt'가 있고 각자의 값들을 가지고 있습니다.
저는 줄 수는 10개로, 시작일은 2020년 3월 10일부터, 종료일은 20210315로 검색하고 싶습니다.
*현재 이 데이터는 페이지를 나누지 않고 줄수도 의미가 없이 한페이지에 모든 데이터를 넣어줍니다.
그래서 그냥 페이지넘버는 1로 하겠습니다.
인증키 자리에 인증키 복사한 것을 넣고

검색 범위에는 이런 식으로 값을 넣어줬습니다.
(5)셀을 실행을 하고 결과를 봅니다.
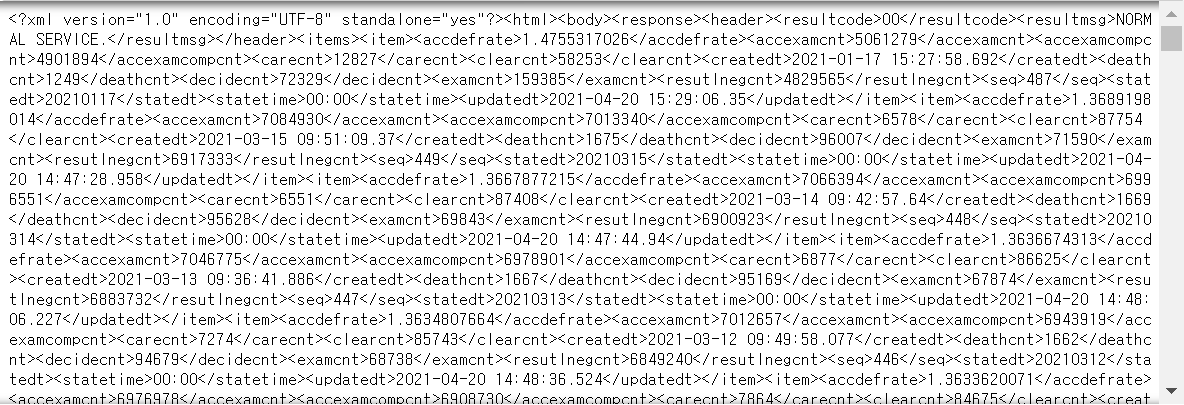
이제는 bs4로 웹페이지를 스크래핑할 때와 유사합니다.
구조를 살펴보면<items>항목안에 <item>항목으로 묶어
<accdefrate>,<accexamcnt>,<accexamcompcnt>,<carecnt>,<clearcnt>,<createdt,deathcnt>,<decidecnt>,<examcnt>,<resutlnegcnt>,<seq>,<statedt>,<statetime>,<updatedt> 를 담고 있는 구조입니다.
(6) item 항목을 모두 다 찾아 줍니다.
items 라는 변수를 지정해주고 item 항목들을 다 items에 넣어줍니다.
items = soup.find_all("item")

그리고 잘 들어가 있는지 items를 실행해 봅니다.
<item>들 별로 다 나오는 것을 확인할 수 있습니다.
이제 <item>항목 안에 있는 항목들의 값을 각각 불러 올 차례입니다.
for 문으로 item이라는 항목에 items[0],items[1]...등등을 items의 길이 만큼 반복하여 저장하게 짜줍니다.
그렇게 해서 각각의 항목들을 item에서 텍스트를 뽑아내서 출력하게 해주면 모든 데이터가 뽑혀져 나옴을 확인할수
있습니다.
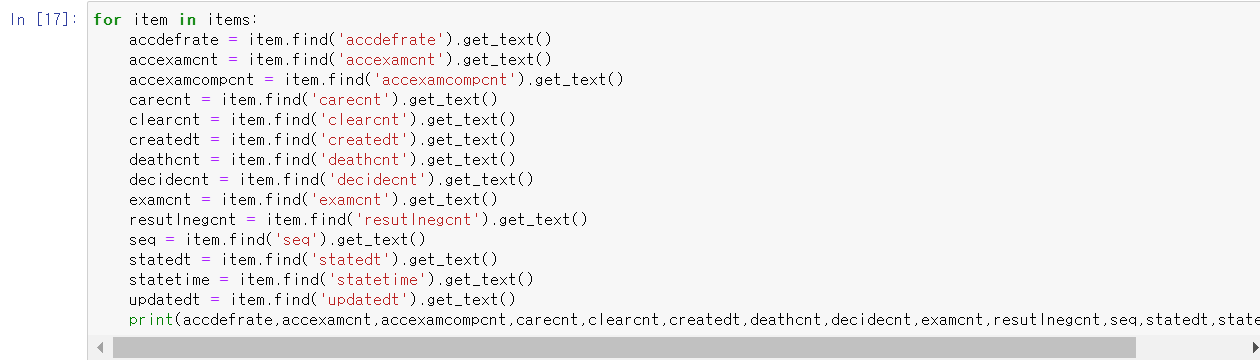
**주의 해야 할 점은 .get_text()로 데이터를 뽑아 낼 경우 Tag.get_text of가 뜨면서 제대로 파싱이 되지 않을 경우가 있습니다. 그래서 get_text()와 .string을 둘다 사용해 보시는 것을 추천드립니다.


xml로 된 공공데이터를 python으로 파싱하는 방법은 여기까지 입니다.
파싱한 데이터들을 이제 자신의 입맛에 맞게 가공하시면 됩니다.
긴 글 읽어주셔서 감사합니다.
'데이터분석 > Python' 카테고리의 다른 글
| 2. dict 자료형 탐색하기 (0) | 2021.08.07 |
|---|---|
| 1. dict 자료형 생성하기 (0) | 2021.08.07 |
| <Python> 자바 파이썬 차이점, 자바 파이썬 적용하기 2(if 조건문, 반복문 for) (0) | 2021.07.27 |
| <Python> 자바 파이썬 차이점, 자바 파이썬 적용하기 1 (0) | 2021.07.25 |
| Jupyter notebook kernel 오류 win32api 오류 수정 재설치 (0) | 2021.07.24 |